Intuitions About Software Development Flow
Tags [ cycle time, flow, optimization, throughput ]
In a previous post, I described the underlying theory behind optimizing the throughput of a software development organization, which consists of a three-pronged attack:
- remove queuing delay by limiting the number of features in-flight
- remove failure demand by building in quality up front and fixing root causes of problems
- reduce average cycle time by experimenting with process
improvements
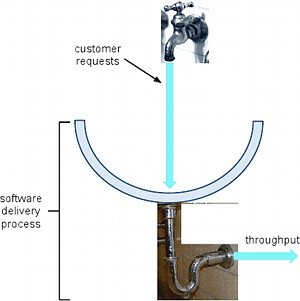
In this article, I’d like to provide an alternative visualization to help motivate these changes. Let’s start with some idealized flow, where we have sufficient throughput to deal with all of our incoming customer requests. Or, if we prefer, the rate at which our business stakeholders inject requests for new features is matched to the rate at which we can deliver them.
Queuing Delay
Now let’s add some queuing delay, in the form of some extra water sitting in the sink:
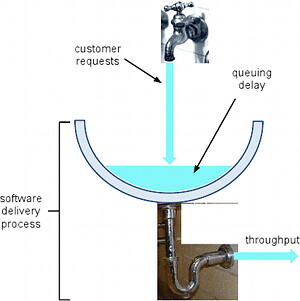
If we leave the faucet of customer requests running at the same rate that the development organization can “drain” them out into working software, we can understand that the level of water in the sink will stay constant. Compared to our original diagram, features are still getting shipped at the same rate they were before; the only difference is that now for any particular feature, it takes longer to get out the other side, because it has to spend some time sitting around in the pool of queuing delay.
Getting rid of queuing delay is as simple as turning the faucet down slightly so that the pool can start draining; once we’ve drained all the queuing delay out, we can turn the faucet back up again, with no net change other than improved time-to-market (cycle time). There’s a management investment tradeoff here; the more we turn the faucet down, the faster the pool drains and the sooner we can turn the faucet back up to full speed at a faster cycle time. On the other hand, that requires (temporarily) slowing down feature development to let currently in-flight items “drain” a bit. Fortunately, this is something that can be done completely flexibly as business situations dictate–simply turn the knob on the faucet as desired, and adjust it as many times as needed.
Failure Demand
We can model failure demand as a tube that siphons some of the organization’s throughput off and runs it back into the sink in the form of bug reports and production incidents:

Our sink intuition tells us that we’ll have to turn the faucet down–even if only slightly–if we don’t want queuing delay to start backing up in the system (otherwise we’re adding new requests plus the bug fixing to the sink at a rate faster than the drain will accommodate). Now, every time we ship new features that have bugs or aren’t robust to failure conditions (particularly common when rushing to hit a deadline), it’s like making the failure demand siphon wider; ultimately we’re stealing from our future throughput. When we fix the root cause of an issue, it’s like making the failure demand siphon narrower, and we not only get happier customers, but we reclaim some of our overall throughput.
Again, there are management tradeoffs to be made here: fixing the root cause of an issue may take longer than just triaging it, but it is ultimately an investment in higher throughput. Similarly, rushing not-quite-solid software out the door is ultimately borrowing against future throughput. However, it’s not hard to see that if we never invest in paying down the failure demand, eventually it will consume all of our throughput and severely reduce our ability to ship new features. This is why it is important for management to have a clear view of failure demand in comparison to overall throughput so that these tradeoffs can be managed responsibly.
Process Change
The final thing we can do is to improve our process, which is roughly like taking all the metal of the drain pipe (corresponding loosely to the people in our organization) and reconfiguring it into a shorter, fatter pipe:
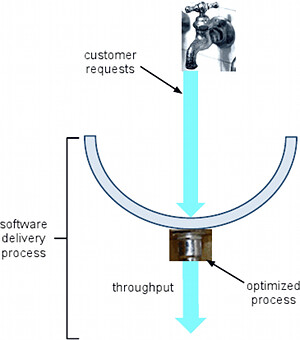
This shows the intuition that if we focus on cycle time (length of the pipe) for our process change experiments, it will essentially free up people (metal) to work on more things (pipe width) at a time, thus improving throughput. There is likewise a management tradeoff to make here: process change takes time and investment, and we’ll need to back off feature development for a while to enable that. On the other hand, there’s simply no way to improve throughput without changing your process somehow; underinvestment here compared to our competitors means eventually we’ll get left in the dust, just as surely as failing to invest cash financially will eventually lead to an erosion of purchasing power due to inflation.
Summary
Hopefully, we’ve given some intuitive descriptions of the ways to improve time-to-market and throughput for a software development organization to complement the theory presented in the first post on this topic. We’ve also touched on some of the management tradeoffs these changes entail and some of the information management will need to guide things responsibly.
Credits: Sink diagrams are available under a Creative Commons Attribution-ShareAlike 2.0 Generic license and were created using photos by tudor and doortoriver.